Last week Long Beach, CA was hosting annual NIPS (Neural Information Processing Systems) Conference with record breaking (8000+) number of attendees. This conference is consider once of the biggest events in ML\DNN Research community.
Below are thoughts and notes related to what was going on at NIPS. Hopefully those brief (and sometimes abrupt) statements will be intriguing enough to inspire your further research ;).
Key trends
-
- Deep learning everywhere – pervasive across the other topics listed below. Lots of vision/image processing applications. Mostly CNNs and variations thereof. Two new developments: Capsule Networks and WaveNet.
- Reinforcement Learning – strong come-back with multiple sessions and papers on Deep RL and multi-arm bandits.
- Meta-Learning and One-Shot learning are often mention in Robotics and RL context.
- GANs – still popular, with several variations to speed up training / conversion and address mode collapse problem. Variational Auto-Encoders also popular.
- Bayesian NNs are area of active research
- Fairness in ML – Keynote and several papers on dealing with / awareness of bias in models, approaches to generate explanations.
- Explainable ML — lots of attention to it.
- Tricks, approaches to speed up SGD.
- Graphic models are back! Deep learning meets graphical probabilistic modeling.
Thoughts on Interpretability
-
- Interpretability vs justification: Are we seeking to understand the real reasons why (or why not) a prediction was made, or merely seeking to justify the prediction and be able to sell its reasonability?
- Most work on interpretability tries to approximate the prediction outcome to highlight some features that were likely responsible for the prediction, i.e., feature selection with post-prediction explanations.
- Interpretability of image models highlights image segments and/or derived maps (heat maps, differential features, ..) that were likely distinguishable for the outcome given.
- Interpretability and fairness are inherently related: How biased are the “explanations” given for a prediction? Are the explanations self-reinforcing a model’s implicit/explicit biases? Does interpretability help or hurt the quest for fairness in ML?
- Interpretability is still limited to a unidirectional explanation, i.e., assuming that the explanation will be consumed (or rejected) in a decision-making process assuming a uniform interpretation of the “interpretable explanation”. The state-of-the-art does not account for diversity of interpretations of the interpretable explanation, nor does it account for the dynamics resulting from human’s reactions and/or adaptations to a prediction + explanation. Model interpretability will be a constantly evolving process due to the human’s perception, adaptation and reactions to the models, similar to the evolution in Web search and social media. ML models are new agents injected in the workplace, society, community, day-to-day life, etc., where they will be subjected to and expected to react to similar dynamics exhibited by their human agent counterparts under a diversity of circumstances.
- Interesting talk by Kilian Weinberger about “The (hidden) Cost of Calibration”. It discusses the positive effects of calibration and its potential impact on interpretability, as well as notions of fairness/unfairness and dangerous side effects. Kilian also shows how Platt’s good old SVM calibration can be applied to the prior-to-last layer weights in deep networks to produce calibrated predictions and overcome model over-confidence.
- FICO is introducing an explainability challenge aiming to produce inherently interpretable credit risk scoring models.
- Interpretability vs justification: Are we seeking to understand the real reasons why (or why not) a prediction was made, or merely seeking to justify the prediction and be able to sell its reasonability?
Overview of talks
Below are notes that give quick gist about what a particular session was about.
A zip archive of all NIPS 2017 papers is available here, good luck with dig into details ;).
| Session | Reinforcement Learning for the People |
| Most impressive breakthrough from the session | Lots of applications that could benefit from RL. |
| Architecture and tech details | Robust and Efficient Transfer Learning with Hidden-Parameter Markov Decision Processes: optimal policies are adapted to subtle variations within tasks in an efficient and robust manner. Bayesian Neural Network both learns the common transition dynamics for a family of tasks and models how the unique variations of a particular instance impact the instance’s overall dynamics.
Sample Efficient Policy Search for Optimal Stopping Domains: can leverage full trajectories to retrospectively evaluate alternate optimal stopping policies; substantial increase in data efficiency. Deep RL Transfer: find good shared representations, fast transfer by encouraging shared representations learning across tasks. Inverse Reward Design — alleviate negative side effects of misspecified reward functions and mitigate reward hacking.
|
| Application (potential) in industry | Shopping optimization (buying airline ticket).
Tutoring games at school. Siemens for industrial environments (“A Benchmark Environment Motivated by Industrial Control Problems”, git here) Medical: prosthesis |
| Other thoughts | Talk gave RL generic overview, the RL for and by the people were discussed.
Here are Stanford slides on “Human in loop RL“, that’s been partially used in the talk. Tutorial http://interactiveml.net/ (section 4) has info on RL by people. Interesting problem on building “Beyond Expectations” systems: policy must be risk sensitive and robust and the same time; safe exploration should be permitted (robotics, self-driving cars). Counterfactual Estimation: active area of research, lots of focus on this in RL works (sequential decision making). Offline policy evaluation across representations with applications to educational games — policy developed for tutoring game by RL was better than policy developed by human. Humans provide demonstrations — enormously influential in robotics; recent tutorial http://lasa.epfl.ch/tutorialICRA16/ . Humans teaching agents needs prep (learn how to do it right). |
| Session | Fairness in ML |
| Most impressive breakthrough from the session | We need to be careful when building models for fairness-sensitive domains (like credit, education, employment, housing, marketing). See legally protected classes.
Observational criteria can help discover discrimination, but are insufficient on their own. Causal viewpoint can help articulate problems, organize assumptions.
|
| Architecture and tech details | How machines learn to discriminate
· Skewed sample · Tainted examples · Limited features · Sample size disparity · Proxies Attacking discrimination with smarter machine learning — threshold classifier, how to turn an unfair classifier into a fairer one. Algorithmic decision making and the cost of fairness — Neither calibration nor equality of false positive rates rule out blatantly unfair practices Avoiding Discrimination through Causal Reasoning – Consider proxies instead of underlying sensitive attributes. |
| Application (potential) in industry | ML in credit, education, employment, housing, marketing verticals. |
| Other thoughts | Slides for the talk: http://mrtz.org/nips17/#/
Discrimination is domain and feature specific. The incidence and persistence of discrimination: 1) Callback rate 50% higher for applicants with white names than equally qualified applicants with black names Bertrand, Mullainathan (2004) 2) No change in the degree of discrimination experienced by black job applicants over the past 25 years Quillian, Pager, Hexel, Midtbøen (2017)
Answer to substantive social questions not always provided by observational data, for example the two scenarios below admit identical joint distributions:
==> motivates causal reasoning |

| Session | Powering the next 100 years/John Platt |
| Most impressive breakthrough from the session | Google AI does really great investments on tacking global problems. |
| Overview | We will need 0.2 Yottajoules (0.2 * 10^24 Joules) over next 100 years, 5x amount of energy consumed by humans so far. Fossil fuel does not scale. Electricity generation is limited by economics .
https://google.github.io/energystrategies/ — modeling e2e system costs. ==> Need to change the game: Fusion energy for example. Google AI collaborates with TAE, helps them on exploration and inference. |
| Application (potential) in industry | Energy sector |
| Session | Reprogramming Human Genome |
| Most impressive breakthrough from the session | ML helped to find super effective drug for Spinal Muscular Atrophy — SPINRAZA.
Current drug development process in ineffective bugdet wise and ML can change that by enabling finding drugs that are more effective and doing that in shorter time (speed up reesearch and clinical trials). |
| Architecture and tech details | Use CNNs (not super complex architecture) to find pathlogic mutations.
Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning.
|
| What data is used | http://tools.genes.toronto.edu/deepbind/nbtcode/
|
| Application (potential) in industry | Medical |
| Other thoughts | Presenter several times mentioned that Biology is too complex for researchers to understand fully.
Described methods genome reprogramming deal with Exons (aka print statements, end up in protein) and Introns(control how Exons are put together). https://www.deepgenomics.com/ — using AI to build new universe of digital medicine. SPINRZA: mutation in Exon (C->T) causes exclusion of this Exon from protein; SPINRAZA modifies sequence to get this EXON included. Testing compounds in cloud lab: Python script with experiment config tells robots how to conduct the experiment. Earning trust and thoughts on Explainability: presenter considers “black box ML” problem to be red herring sometimes. Groundbreking results and awesome perf results that ML approach is super helpful with earning trust from stakeholders.
|


| Session | Test of time award: Random Features for Large-Scale Kernel Machines (NIPS 2007) |
| Most impressive breakthrough from the session | Presenter made conversial statement that current state of ML is similar to Alchemistry — it’s works and often useful but people do not always fully understand how it works. DNN tools are fragile.
Advances in “black-box” and more difficult to interpret algorithms come at a price. Need to reinstate rigor in scientific methods. Simplicity does not imply less power. |
| Overview | Gist of the paper that got award: most of the kernels used in 10 years ago could be approximated as straight sum of product kernel functions => approximation gives linear combination with less coefficients to solve for and that was what optimizers at that time could handle.
Do not underestimate the effect of compounded errors/approximations on model training (e.g., SGD computation on different hardware) |
| Session | Robust Optimization for Non-Convex Objectives |
| Most impressive breakthrough from the session | Potentially promising approach to deal with noisy data (image related). |
| Architecture and tech details | Link to paper. Goal is to find a minimax solution that optimizes in the worst case over a given family of functions.
Example: character classification over images that are subject to various distortions(patterned backgrounds or low-resolution, or rotations). Instead of training a separate classifier for each possible scenario this approch aims to optimize performance in the worst case over different forms of corruption. Those corruptions (functions)are provided to the trainer as black-boxes. Git. |
| What data is used | MNIST |
| Application (potential) in industry | Robust neural network training. Presenters demoed character classification task with adversarial distortion (corrupted, noisy data) |
| Other thoughts | All demos were MNIST related (basic). |
| Session | The Trouble with Bias |
| Most impressive breakthrough from the session | Author showed overwhelming example of biases we come across in Search, Recommender System, Computer vision and other ML related scenarios.
Biases reflect our culture and history of the society. Datasets reflect who is in power. Datsets get outdated. |
| Overview | Bias\fairness theme is often mentioned at the conference.
Harms of allocation — we’re here now. — stereotyping, race related issues with computer vision, denigration (jews, skin color), underrepresentation (women execs) Harms of representation — what we’re missing. Celebrity face dataset: 70% men, 80% of those are white man, the most popular person is J. Bush (dataset was built of news articles). What can we do? – Forensics of the data and it’s lifecycle. – Working with people who are not in our group – Be mindful of ethics of classification Video of the talk here. |
| Application (potential) in industry | Well, everyone where personal data (including computer vision) is involved. |

| Session | Streaming Weak Submodularity: Interpreting Neural Networks on the Fly |
| Most impressive breakthrough from the session | Much faster (10x?) than LIME |
| Architecture and tech details | Paper is here. Git is here.
Segment an image into N superpixels. Then, for a subset S of those regions create a new image that contains only these regions and feed this into the black-box classifier. For a given model M, an input image I, and a label L1 we ask for an explanation: why did model M label image I with label L1.
|
| Application (potential) in industry | Computer vision. |

| Session | A Unified Approach To Interpreting Model Predictions |
| Most impressive breakthrough from the session | Claims to combine the best of 6 model explainability approaches. Has integration with xgboost.
Show improved computational performance and/or better consistency with human intuition than previous approaches. |
| Architecture and tech details | Paper is here. Git is here. , SHAP (SHapley Additive exPlanations) assigns each feature an importance value for a particular prediction. |
| What data is used | For computer vision: MNIST |
| Other thoughts | Feature independence is assumed.
|

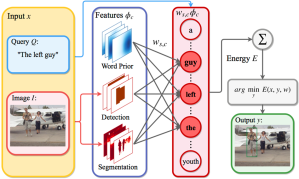
| Session | Interpretable and Globally Optimal Prediction for Textual Grounding using Image Concepts |
| Most impressive breakthrough from the session | Combines object detection, image semantic segmentation, and word embeddings to capture spatial-image relationships and provide interpretability. Searches all possible bounding boxes efficiently.
Approach outperforms current methods accuracy by 3%+. |
| Architecture and tech details | Project page here.
Words priors: the average bounding box location per word. Ws,c — connects word s to and image concept c. Intuition: if word s and concept c are related , then |Ws,c| is large.
Φc — accumulated value withing bouding box y for image concept c. Learning params: Structured SVM |
| What data is used | Flickr 30k Entities and the ReferItGame database |
| Application (potential) in industry | Joint understanding of language and image. |
| Other thoughts | Success case:
Interpreting learned params — word-concept relationships |Ws,c|. Concepts are from object detection.
Grounding image and text concepts is bi-directional: Ground text to image concepts (this paper) or ground image features to text concepts (VQA paper above). Paper compares to other techniques, including CCA (note to self: check CCA previous work and possibility of bi-directional concept grounding) |



| Session | Label Efficient Learning of Transferable Representations across Domains and Tasks |
| Most impressive breakthrough from the session | Learns a representation transferable across different domains and tasks in a label efficient manner.
Model is simultaneously optimized on labeled source data and unlabeled or sparsely labeled data in the target domain. |
| Architecture and tech details | 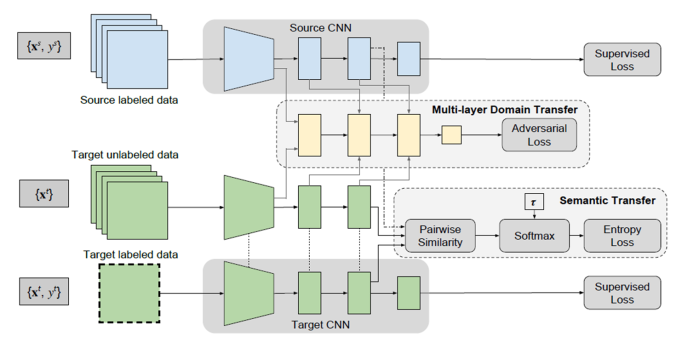 |
| What data is used | Transfer learning SVHN 0-4 –> MNIST 5-9
Transfer learning ImageNet object recognition –> video action recognition |
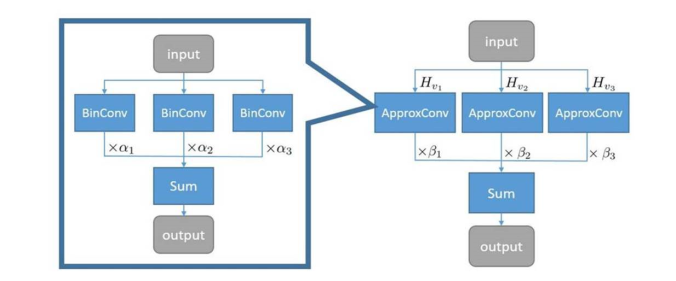
| Session | Towards Accurate Binary Convolutional Neural Network (ABC-Net) |
| Most impressive breakthrough from the session | Authors claim that this is the first time a binary neural network achieves prediction accuracy
comparable to its full-precision counterpart on ImageNet. |
| Architecture and tech details | Paper is here.
Binaries NNs (BNNs) have extreme case of quantization: binary weight and activation +-1 using sign() function. Competitive on MNIST, falls apart on ImageNet (18% accuracy loss). Fix: approximate weights and activations more precisely. 1. Approximate full-precision weights with the linear combination of multiple binary weight bases. The weights values of CNNs are constrained to {−1, +1}, which means convolutions can be implemented by only addition and subtraction (without multiplication), or bitwise operation when activations are binary as well. Paper shows 3∼5 binary weight bases are adequate to well approximate the full-precision weights. 2. Introduce multiple binary activations. Employing five binary activations reduces the Top-1 and Top-5 accuracy degradation caused by binarization to around 5% on ImageNet compared to the full precision counterpart.
|
| What data is used | ImageNet |
| Application (potential) in industry | Computer vision on smaller devices (drones, mobile) |
| Other thoughts | Main motivation for the paper was to run CNNs on DJI Drones, that have limited resources in computation and power. |
| Session | The Unreasonable Effectiveness of Structure |
| Most impressive breakthrough from the session | Key question of the talk: Is there structure in the problem and how can I exploit it?
PSL framework is introduced PSL has produced state-of-the-art results in many areas spanning natural language processing, social-network analysis, and computer vision. Exploiting structures in inputs and outputs of ML models · Data is multi-modal, multi-relational, spatio-temporal · Dependencies and structure in outputs are often ignored, thereby making incorrect independence assumptions. |
| Architecture and tech details | Probabilistic Soft Logic (PSL) is a machine learning framework for developing probabilistic models.
PSL Program = Rules + Input DB PSL program:
|
| Application (potential) in industry | Natural language processing, social-network analysis, computer vision (image reconstruction, activity recognition in videos), entity resolution, recommendation systems, knowledge discovery (graph construction, knowledge completion), debate stance classification, trust relationships. |
| Other thoughts | Structured prediction patters:
· Collective Classification Votes(X,P) & Friends(X,Y) -> Votes(Y,P) · Link Prediction Likes (User, Item1) &SimilarItem(Item1, Item2) -> Likes(User, Item2) · Entity Resolution Determine which nodes refer to same underlaying entity
Dangers of ignoring structure: · Privacy: 1. Many approaches consider only individuals’ attribute data 2. Don’t take into account what can be inferred from relational context -Fairness 1. Impartial decision making 2. Need to take into account structural patterns Opportunity for ML methods that can mix: · Structured and unstructured approaches · Probabilistic & logical inference · Data-driven &knowledge driven modelling |

| Session | Engineering and Reverse-Engineering Intelligence Using Probabilistic Programs, Program Induction, and Deep Learning |
| Most impressive breakthrough from the session | Deep integration of probabilistic programming with deep learning to capture “common sense” inferences, inverse planning, inverse graphics (inferring 3d scene structure from 2d images) |
| Architecture and tech details | Many languages for probabilistic modeling. Tutorial uses Venture. |
| Application (potential) in industry | Robotics, computer vision (scene understanding), interactive (thinking) systems |
| Other thoughts | Got AI tools and techniques, but not real AI.
AI and robotics hasn’t reach intelligence of an 18-months old baby yet. Engineering common sense using probabilistic models. |
| Session | Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results |
| Most impressive breakthrough from the session | A method to overcome limitations of temporal ensembling. Averages model weights instead of label predictions. Achieves good test results with fewer labeled examples. Works with residual networks too. |
| Overview | Semi-supervised learning using two models: student and teacher, that improve each other during training. Target-generating teacher model. Improves results on CIFAR-10 and ImageNet. Can be potentially combined with a virtual adversarial technique to further improve results by improving target generation. |
| What data is used | CIFAR-10 and ImageNet |
| Session | Attention is all you need |
| Most impressive breakthrough from the session | Proposes a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely |
| Architecture and tech details | https://github.com/tensorflow/tensor2tensor |
| Application (potential) in industry | Machine translation Potentially any application involving sequence learning, assuming that components are independent |
| Session | A simple neural network module for relational reasoning |
| Most impressive breakthrough from the session | Introduces Relation Networks (RNs) as a simple plug-and-play module to solve problems that fundamentally hinge on relational reasoning. |
| Architecture and tech details |  |
| What data is used | CLEVR, Sort-of-CLEVR, bAbl A simulated dataset of dynamic physical systems |
| Application (potential) in industry | Visual question answering
Text-based question answering Potentially any application that requires learning relations between features (uni or multi-modal features) |
| Session | Deep Voice 2: Multi-Speaker Neural Text-to-Speech |
| Most impressive breakthrough from the session | Technique for augmenting neural text-to-speech (TTS) with low-dimensional trainable speaker embeddings to generate different voices from a single model. |
| Architecture and tech details |  |
| What data is used | VCTK and Audiobooks |
| Application (potential) in industry | Single and multi-speaker text-to-speech systems Natural sounding digital assistants and animated audiobook readings |
| Other thoughts | Shows that a single neural TTS system can learn hundreds of unique voices from less than half an hour of data per speaker, while achieving high audio quality synthesis and preserving the speaker identities almost perfectly. |
| Session | Modulating early visual processing by language |
| Most impressive breakthrough from the session | Visual question answering. E.g.: Answer question about an image “is the umbrella upside down?”
Modulates entire visual processing by a linguistic input. |
| Architecture and tech details |  |
| What data is used | VQA and GuessWhat?! |
| Application (potential) in industry | Visual question answering |
| Other thoughts | Inspiration related to another paper which grounds image-based features using text concept words: Interpretable and Globally Optimal Prediction for Textual Grounding using Image Concepts |
| Session | TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning |
| Most impressive breakthrough from the session | Speed up to up to 1.5-2x for distributed training.
Gradient is quantized to three levels {-1, 0,1} |
| Architecture and tech details | Git repo and slides.
Only exchange gradients. Gradient quantization reduces communication in both direction.
|
| Application (potential) in industry | Distributed DNN training in cloud. |
| Other thoughts | TernGard give higher speed up when:
· Using more workers · Using smaller communication bandwidth · Training DNN with more fully connected layers
|

| Session | Train longer, generalize better: closing the generalization gap in large batch training of neural networks |
| Most impressive breakthrough from the session | Investigate different techniques to train models in the large-batch regime and present a novel algorithm named “Ghost Batch Normalization” which enables significant decrease in the generalization gap (= persistent degradation in generalization performance) without increasing the number of updates. |
| Architecture and tech details | Paper here. Git here.
· Experiments show noticeable generalization gap between small and large batch (Resnet on Cifar10: 92.8% vs 86.1%). · After adapting learning rate results improved but gap remained (92.8 vs 89.3) · Ghost batch norm: mimic small batch statistic; also reduces communication bandwidth (92.8 vs 90.5). Acquiring the statistics on small virtual (ghost) batches instead of the real large batch helps to reduce the generalization error (Note: use full batch statistic for the inference phase) · Then train longer in plateau region (Regime Adaptation)-> generalization gap vanishes (92.8 vs 93.7).
|
| What data is used | MNIST, CIFAR-10, CIFAR-100 and ImageNet |
| Application (potential) in industry | Significant speedup are possible:
“Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour” (paper) uses 8K batch size, adopts a linear scaling rule for adjusting learning rates as a function of minibatch size and develops a new warmup scheme that overcomes optimization challenges early in training. |
| Other thoughts | Motivation: Can we improve batch size and improve parallelization? |

| Session | Deep Learning for Robotics |
| Most impressive breakthrough from the session | Recurring theme: Meta-Learning. Enables discovering algos that are powered by data\experience (vs just human integrity) |
| Overview | Current areas of research\not solved yet:
· Faster RL · Long horizon reasoning · Trackability · Lifelong learning · Leverage simulation · Maximize Signa Extracted from Real World Experience Overview of Deep RL success stories. See list of Berkeley papers here. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (MAML, paper) has been presented at ICML and mentioned here again several times. Lots of work on applying meta-learning to Optimization (task distribution: different NNS, weight inits, diff loss funcs). Lots of work on applying meta-learning to Classification (task distribution: diff classification datasets). Lots of work on applying meta-learning to RL (task distribution: different envs) |
| Session | Learning State Representations |
| Most impressive breakthrough from the session | “Shallow learning, deep representations” – sophisticated learning of problem representation makes learning task simple |
| Overview | Working on AI that is more like human intelligence (crossing street vs chess). “simple” tasks with little data.
Key question: How do we learn a representation of the world that supports decision making? Hypothesis: people group similar environments as originating from same cause: Bayesian inference with infinite capacity prior – latent causes, number unbounded. Real world learning is clustering with growing number of clusters Orbitofrontal cortex in humans implicated in making “good life choices”, but can still function normally. Hypothesis is that it encodes hidden causes. |
| What data is used | Experiments: guessing number of circles; direction of line on screen; Face/House-Young/Old task |
| Session | AlphaZero – mastering games without human knowledge |
| Most impressive breakthrough from the session | AlphaGo Zero learns no human data – just from rules + self-play, starting random.
No human features – just raw board Single policy/value network No Monte-Carlo – just NN evals. “Less complexity => more generality” Search-based policy iteration 1. Search-based policy improvement (instead of greedy) 2. Search-based policy evaluation (this allows evaluation of improved policy, giving even better training signal) Now recently applied to Chess. Despite structural differences, used exact same model for chess. Within 4 hrs outperformed world champion. Specialization hurts generalization ability. |
| Architecture and tech details | MCTS = Monte Carlo Tree Search works better than Alpha-Beta search. |
| Other thoughts | Advance over AlphaGo.
Go is 3k years old, 40M players, 10^70 positions Intractible to search because of ^200 branching 2 networks: 1. Move – generates distro over moves – reduce breadth 2. Value – predicts winner given position – reduce depth During world champion game saw “systematic delusion”. Fixed in new version using “principled RL” Autonomously discovered well known openings used by humans. Also discovered new patterns adding to human knowledge. Chess – current state-of-the-art superhuman. Alpha-beta search based on human expertise. Stockfish: 1. Long list of specialized features |
That be all what have been captures which is tiny part of what’s being covered at the conference :).

Reblogged this on Marketing Analytics.
LikeLiked by 1 person
I have read so many articles or reviews regarding the blogger
lovers however this article is really a pleasant piece of writing, keep it up.
LikeLiked by 1 person